

This is a follow-up post to my analysis of using Azure NetApp Files for AKS storage versus the native solutions. After I wrote the post, with some surprising findings about Azure File performance, a number of people from Microsoft reached out to bring up a few key facts. In this post I will review the points that they brought up and include an updated analysis of the native Azure storage solutions for the Azure Kubernetes Service. Hold on to yer butts everyone!
There are basically two native solutions on Azure to provide persistent storage to AKS, Azure Managed Disks and Azure Files. In my original assessment, I used the Standard and Premium tiers of Managed Disk, but only the Standard tier for Azure Files. Either I misread the documentation or it was updated after my initial reading - this is the cloud after all and stuff is changing by the moment - and I thought only the Standard tier was supported for Azure Files. The Premium tier is definitely supported, and that is one of the things that the folks from Microsoft wrote in to let me know.
They also wanted to bring it to my attention that performance on premium storage is highly dependent on the amount of storage presented. That goes for both Managed Disk and Azure Files. Basically, the more storage you allocate, the more IOPS and throughput you get. I can only assumed that in both cases you are getting the aggregated throughput of multiple disks on the back end. By only using a single disk size of 500GB for my testing, I was restricting the max throughput of the Premium Managed Disk to 2300 IOPS and 150MBps. Standard tier for Managed Disks and Azure Files have a performance level that is unaffected by capacity, except in the case of very large disk sizes for Standard HDD disk. Standard HDD disks are pegged at 500 IOPS and 60MBps, which matches my findings of 555 IOPS and ~62MBps. Standard Azure Files are pegged at 1000 IOPS regardless of size, although apparently a 10K IOPS option is coming in the near future for larger file shares.
Another thing I discovered is that the default storage class for Azure Managed disks uses the Standard HDD class of disk and not Standard SSD. I was moderately surprised by this discovery, as I would expect Standard SSD to be the default for any new storage out there. The performance levels for IOPS and throughput are roughly the same, but Standard SSDs deliver lower latency. Standard SSDs do cost about 30% more, so maybe they were trying to save money for users? Who knows.
I also needed to consider the IO limitations of the Azure VM I was using for my AKS cluster. In my original test I was using the DS2_v2 class of Azure VM. The DS2_v2 has a max of 6400 IOPS and 96 MBps throughput for uncached workloads. The max bandwidth on the NICs is 1500Mbps, which is roughly 187.5MBps. The way I understand it, Azure Managed Disks are directly attached to the VM, so they are beholden to the storage restrictions of 6400 IOPS and 96MBps. Azure Files and the Azure NetApp Files are using the NICs to mount the storage, so their restriction would be the NIC bandwidth of 187.5MBps and whatever IOPS the storage solution can push. Looking at the data from my previous testing, the max throughput was Azure Files at 193MBps for a Read workload. Slightly above the stated limit, but not way outside of tolerances. The max IOPS for Managed Disks was 8159 for a Read workload. Again, above the limit of 6400, but not wildly out of spec. There could definitely be some caching going on as well.
Lastly, the Ultra tier of Azure Managed Disks is now GA. The performance of Ultra disks scales with capacity and has a theoretical max of 160,000 IOPS and 2,000MBps throughput for a 1TB disk. They are only supported on the ES and DS v3 Azure VMs, in select Azure regions, and must be deployed in an availability zone.
In lieu of all the feedback I received, and things I discovered after the fact, it would appear that I need to update my testing methodology. First of all, I need to use a different family of VM for testing. The maximum IOPS for all the ES and DS v3 VMs is 128,000 cached or 80,000 uncached. The max throughput is 1024MBps cached or 1200MBps uncached. Based on the specs for the Ultra disk tier, I cannot select a VM that would actually achieve the max performance for a 1TB disk. To achieve the maximum available throughput, I will need to use a D64s_v3 VM, which will run me about $3.07 per hour. The price you pay for glory I suppose! If I want to test the Ultra tier, the AKS cluster will need to be created using the availability zone option in the East US 2 region.
I will test all six options for storage, with different sizes for each. Here is the rough testing matrix:
| Storage Type | Storage Class | Storage Size |
|---|---|---|
| Managed Disk | Standard HDD | 1TB |
| Managed Disk | Standard HDD | 10TB |
| Managed Disk | Standard HDD | 20TB |
| Managed Disk | Standard SSD | 1TB |
| Managed Disk | Standard SSD | 10TB |
| Managed Disk | Standard SSD | 20TB |
| Managed Disk | Premium SSD | 1TB |
| Managed Disk | Premium SSD | 10TB |
| Managed Disk | Premium SSD | 20TB |
| Managed Disk | Ultra SSD | 1TB |
| Azure Files | Standard | 1TB |
| Azure Files | Standard | 5TB |
| Azure Files | Premium | 1TB |
| Azure Files | Premium | 10TB |
| Azure Files | Premium | 20TB |
You’ll note that the Ultra Disk is only using a 1TB size. According to the documentation, any Ultra disk above 1TB has the maximum available performance, and therefore I see no reason to spend more money on a larger disk. The max size for an Azure Files Standard share is 5TB. Since the performance on the Standard Files is capped anyway, it probably doesn’t matter.
For the testing software, I am going to be using the same FIO project, with the same environment variables as last time.
env:
- name: DBENCH_MOUNTPOINT
value: /data
- name: DBENCH_QUICK
value: "no"
- name: FIO_SIZE
value: 1G
- name: FIO_OFFSET_INCREMENT
value: 256M
- name: FIO_DIRECT
value: "1"
Before I get to the results, I discovered several things during my testing that bear mentioning. First, there are two storage classes in AKS by default, default and managed-premium. As I mentioned before, the default class uses Standard HDD. What I didn’t realize until the test is that it has cachingMode set to ReadOnly. After the first test run, I saw that my Random IOPS Read test was getting 180k IOPS on the Standard HDD. That seemed… wrong. I ended up creating a new storage class called managed-standard-hdd with cachingMode set to None. Same thing with the managed-premium storage class.
I also learned that managed disks are provisioned in an availability zone, but not in a deterministic way. The managed disk would be provisioned in any zone that was part of the cluster definition, and if I didn’t have a node in that zone, the disk would never attach. To repeat that, managed disks in an availability zone can only attach to VMs in the same availability zone. If you are like me and trying to keep costs down by having a single node running in the cluster, then there’s a 66% chance the disk will be created in a zone where you don’t have a node. You can either running N number of nodes, where N is equal to the number of availability zones in your AKS cluster, or manually create the managed disk and set it to the same zone as your one node.
Configuring Ultra SSD was also challenging. So challenging, in fact, that I ended up reaching out to the AKS product team for help. Big shout out to Justin Luk and Jorge Palma for the assistance. I will cover the process of getting Ultra SSD working in a separate post, since this post is already fairly large.
Finally! To the numbers!
As in my initial post, we are first going to look at bandwidth for both random and sequential workloads.
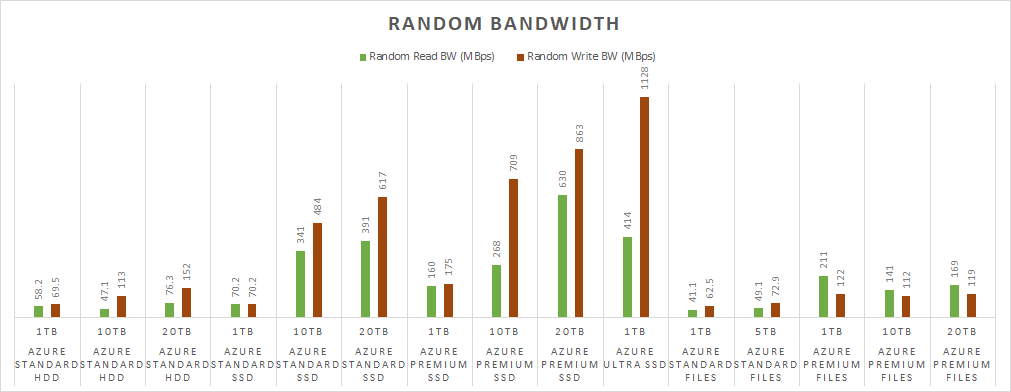
It’s pretty obvious from the chart that the Ultra SSD crushed the random write test. It maxed out at basically 1GBps of bandwidth for random writes. I provisioned the Ultra SSD disk with 2000MBps of bandwidth, but as I mentioned earlier the max for a D64s_v3 VM is 1200MBps for uncached. I was hitting the limitation of the VM, not the Ultra SSD. It was a little surprising that the random read test came back under the Premium SSD numbers. I attribute this to the smaller volume size. Even though I am supposed to be able to get 2000MBps of throughput on a 1TB volume, there may be an advantage to provisioning more storage.
Aside from the Ultra SSD, it’s notable that Standard SSD drives at 10TB and 20TB are not that far behind the Premium SSD, and they also blow the Standard HDD out of the water for bandwidth. The key takeaway here is, if you want more performance from the Standard and Premium SSD disks, then you need to provision more storage. With Azure Files that does not appear to be the case. Even with 20TB of Azure Premium Files, the throughput was still about the same as 1TB.
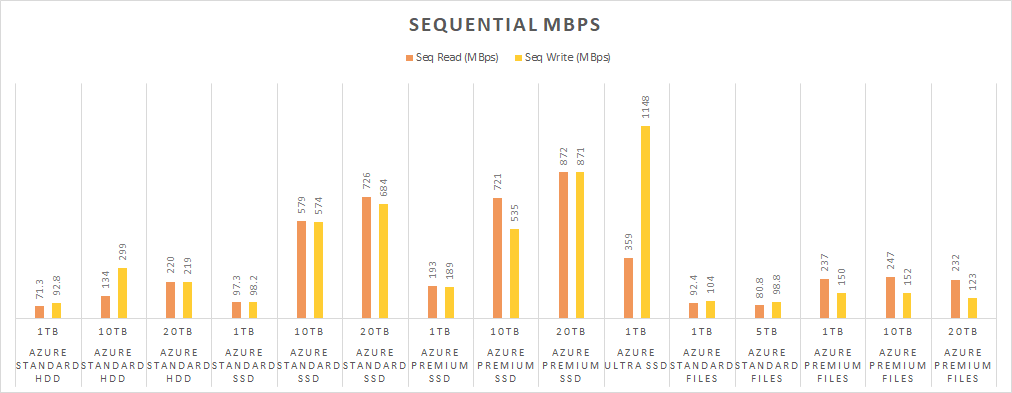
Once again, the Ultra SSD crushed it for sequential write, but not for sequential read. At least it’s a consistent result. The Standard HDD disks did a lot better for sequential work, and that’s not surprising for a spinning medium. 20TB of Standard HDD actually did better than the 1TB of Premium SSD and matched the performance of Azure Files.
Now let’s move on to IOPS.
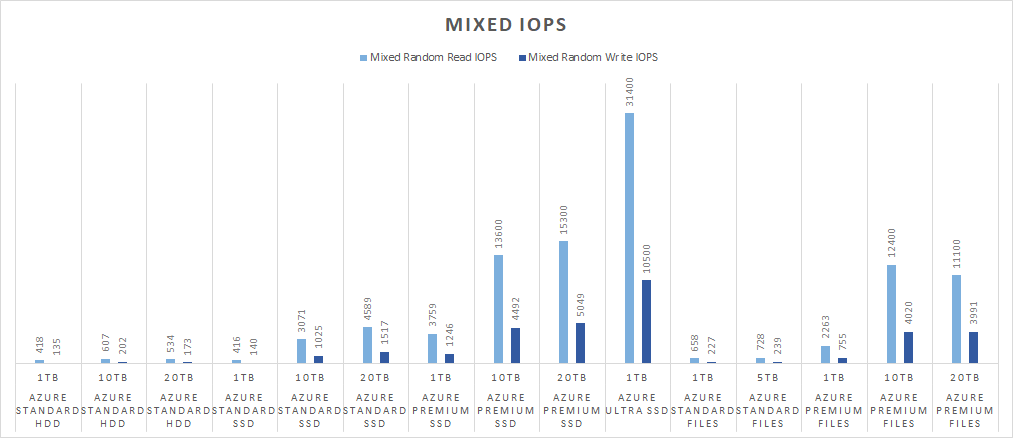
We can’t be terribly surprised that Ultra SSD killed it for IOPS can we? Remember I provisioned 160,000 IOPS for the Ultra SSD disk and I only hit 31,400. The max for the VM type is 80,000 IOPS, so I also wasn’t maxing out the VM. I’m not sure whether the IOPS limitation was on the CPU side or something to do with the container? Regardless, the max I got for NetApp’s Ultra tier was 32K IOPS, so the Ultra SSD disks are comparable. It’s also worth noting that Premium SSD and Premium Files were pretty similar in IOPS performance. Doing a quick cost exercise, 10TB of Premuim SSD is $1,638 and 10TB of Premium Files is $1,536. Azure Files charges for write, list, and read operations, so it would be a wash cost-wise. The nice thing is that Azure Files are network based and thus you don’t have to worry about the zonality of storage and the storage can be shared across multiple pods if desired.
I’d also like to point out that Standard SSDs really start performing at a capacity larger than 1TB. The performance between a 1TB SSD and 1TB HDD is very similar. But a 10TB SSD blows the 10TB HDD out of the water. Standard SSDs are more expensive than Standard HDD, but despite what the official numbers say on Microsoft’s docs, there is a significant performance difference in IOPS.
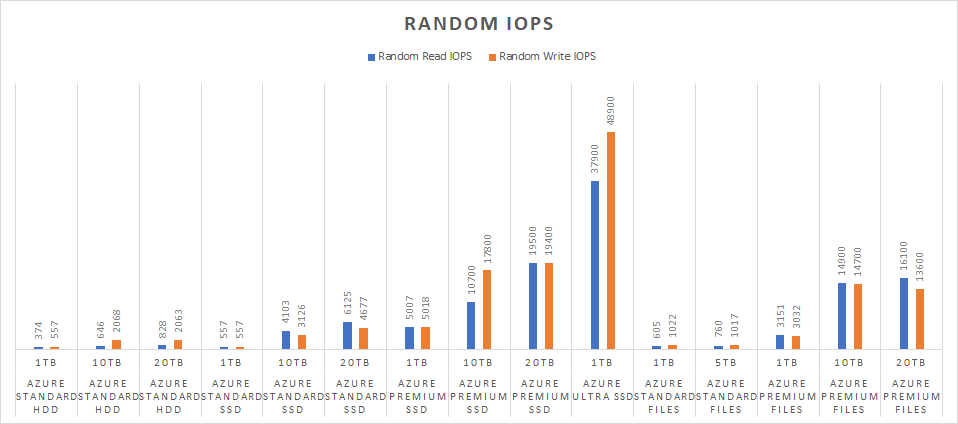
Here’s where the Ultra SSD really shined. Peaking at 48,900 IOPS for random writes, we still haven’t hit the VM or Ultra SSD maximums. There should still be more performance to be eked out if the proper tweaking was in place. Just as in the Mixed IOPS, the Premium SSD and Premium Files were fairly close in performance. The Standard SSD continued its pattern of outperforming the Standard HDD at larger sizes.
I am not going to include average latency here. The results I got out of FIO were inconsistent and sometimes missing entirely. The Standard HDD was showing lower read latency than the Ultra SSD, for example, and I am pretty certain that isn’t correct.
There’s probably a few key takeaways here. First, the amount of storage provisioned matters. Whether it’s standard or premium storage, more storage tends to results in better performance. It’s not a surprising result, but I am glad to see it proved out. Second, the VM type matters as well. My initial tests were performed on a VM that was undersized to the task. Third, the default storage classes may not match what you want in your AKS cluster. Definitely consider creating custom storage classes that define exactly what you are looking for. Finally, the Azure managed disks can only be attached to a single VM in a single zone. For the moment, that prevents them from being particularly useful to stateful workloads on an AKS cluster using availability zones. You’re going to need to go with Azure Files or some other network based solution.
Going forward I would like to tweak my testing to run each test multiple times and aggregate the data across runs to even out anomalies. I’m thinking I would need to have the container push the logs to an Azure Files share in JSON format, and then have something that ingests the logs and does the number crunching. But that is a story for another day.
May 23, 2026

May 4, 2026


