

As a Cloud Field Day 5 delegate, I attended a presentation from Pure Storage regarding how their products are embracing the cloud. Whenever a storage vendor starts talking about embracing the cloud, I start to get a bit wary. In general, what they actually mean is they have created a virtualized version of their array, running on IaaS, using the public cloud. Or it could mean that they now have the ability to send data up to the public cloud from a local datacenter. Is that what Pure came to the table with? Yes. At least that was part of the presentation, but they actually had additional product details that I felt moved the needle and showed some real innovation.
The initial product direction and vision for the company had some interesting points. The central theme was the divide between what storage looks like in a traditional datacenter versus the cloud. When you think of cloud storage, you probably think of a few key factors:
Traditional storage is very much the opposite of how cloud approaches these three categories. You almost always pay up front for capacity, with the exception of some larger programs from storage providers where you pay as you go (PAYG). But even those programs are limited in the amount of capacity you can consume in the PAYG model. Traditional storage is also limited in capacity and performance. A storage array has whatever capacity it has. You can expand that capacity up to a point, but eventually you will run out of room on the frame and have to buy another frame. That second frame is not part of the same storage service, unless you have invested in something like a VPLEX, but even then there are limits. And you can’t shrink down when you don’t need the storage anymore. Releasing capacity back into a storage pool is fraught with peril, and even if you successfully accomplish this feat you can’t exactly return the disks to the vendor for a refund. Lastly, the interaction with traditional frames is usually through some command line tool, or a janky UI that uses some outdated and insecure version of Java that only works on one workstation in the company, and you all RDP into that workstation to make changes to the frame. Not that I have any experience with something like that…
ANYHOW.
Pure’s main point was that traditional storage needs to take its cues from cloud storage and find a way to embrace those three principles, as well as support object-based storage, instead of just file and block.
There were two products showcased by Pure during the demos.
Remember that thing I said about storage vendors sending data up to the cloud? Yeah, that’s basically what Cloud Snap is. You can watch the whole presentation if you like, but I can distill it down to the essential components. Cloud Snap replicates a snapshot from a Pure array to either NFS or AWS S3. After the first snapshot, each update only sends the incremental differences, which makes the storage consumption and network consumption fairly efficient. The snapshots include the metadata about the snapshot, so the snapshot can be recovered to any Pure array and not just the original array. Cloud Snap doesn’t use a virtual appliance in the public cloud destination, it manages the storage from the array itself. The presenter talked about using the replicated storage in tandem with backup software to efficiently move data to a cloud target. While that seems like a potential application, most of the backup providers are already using their own deduplication and compression algorithms to efficiently move data between targets. Instead, this seems more like a way to reduce space consumption on the array and provide offsite data protection for a crash consistent DR recovery.
Not a terribly innovative solution overall, but it seems to be table stakes for storage vendors these days.
Remember that thing I said about running a virtual frame on IaaS in the public cloud? For starters, that’s not a great idea. You’re going to end up spending a lot of money on the IaaS, and in all likelihood the virtual version of the frame has the same limitations that the original frame had. It probably makes more sense to replicate data using some other third party tool. The Cloud Block Store is a straight port of their on-premises frame - more on this later. It’s using a combination of S3 and EC2, and each instance is deployed in a single availability zone. You can set up a synchronous cluster of instances across AZs, but you cannot stretch a single instance across more than one AZ.
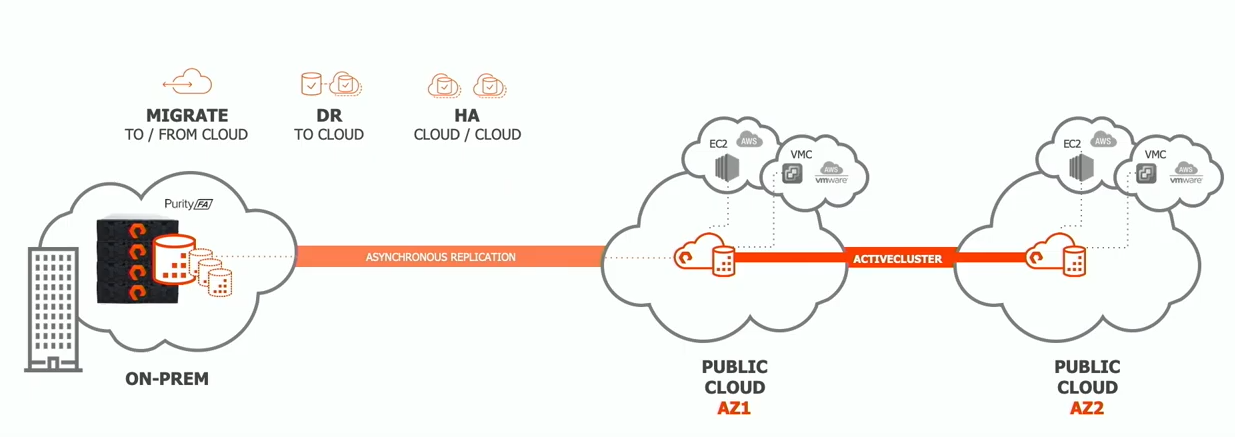
I thought that was a strange choice, and I asked about the decision to have the instance run in a single AZ instead of multiple AZs. The presenter talked about the mental model of what they were trying to create, which I took to mean that they are focused on building something that looks like a traditional datacenter. In the traditional world, this would be the equivalent of creating a metro-cluster with the VMAX. But I would remind you that this is a cloud product, and apparently it is using S3, which is a multi-AZ service. There is no reason to mimic the traditional datacenter approach when it brings no tangible benefit. It seemed clear from the remainder of the conversation that the team from Pure knows this, and once Cloud Block Store is a out of beta and a few revs into its production lifecycle, the instance will be multi-AZ capable.
The front-end of the Cloud Block Store uses the same APIs as a Pure Storage array, so any application that works with the on-premises array will work with the Cloud Block Store. The presenter showed an example where both versions were using the Pure Service Orchestrator to provision storage on the fly for a Kubernetes cluster. It was an interesting concept, but K8s already has native cloud integrations for storage. I don’t necessarily know why I would want to shove the Cloud Block Store into the mix. I suppose you could be replicating data from an on-premises array to Cloud Block Store and running a application on K8s that is running in both environments and consuming the replicated data. Maybe for a DR site? I guess what I’m saying is that it’s possible to do. I just don’t know if this is the killer use case for most people.
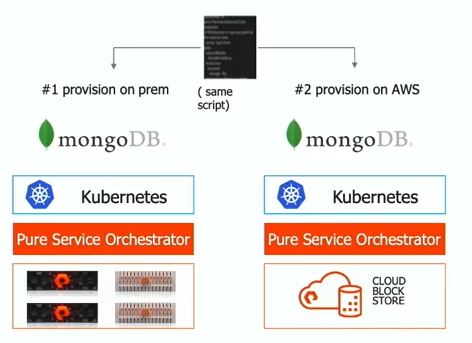
I like that Pure is at least thinking of ways to integrate with modern development methods. It’s far and away better than some storage vendors out there who can’t really think outside the LUN. Does that make them the Taco Bell of storage vendors? Maybe, and I mean that as a compliment.

Towards the end of the presentation, Pure mentioned that they had rewritten the Purity software that runs their array for Cloud Block Store. I want to emphasize that. They rewrote the Purity software to take advantage of the native constructs within AWS. This is not just a straight port of their array software running on a virtual machine and backed by traditional data disks. The API front-end is the same as their on-premises product, but the backend is something completely different. That’s HARD. And when companies do something hard, it shows a level of commitment to this cloud thing that I don’t always see with traditional vendors.
Pure Storage is certainly doing some interesting things with their cloud offerings. They appear to have the basics covered, and are doing their best to bring some real innovation to their cloud products. If you are already all in with Pure on-premises, then expanding out to the cloud with the same management tools and APIs might make a lot of sense. There could be the fear of vendor lock-in, but I take those fears with a grain of salt. As soon as you pick any technology, you are “locked in.” I’m excited to see where Pure goes from here, especially once Cloud Block Store exits the beta stage and customers start putting Production workloads on it. Once a product is in customers hands, they often think of use cases that the product team never considered.
May 23, 2026

May 4, 2026


