

Recently, I was a guest on the Azure DevOps Lab YouTube channel, talking about using GitHub Actions with Terraform to deploy infrastructure on Azure. April Edwards was a gracious host and let me ramble on for 10+ minutes about the very basics of GitHub Actions. Due to the short format of DevOps Lab videos, I wasn’t able to really dig into specifics around the GitHub Actions file. I thought I would write a blog post to fill in the gaps, and so here we are.
DevOps Lab on Getting Started with GitHub Actions and Terraform
As I mentioned in the video, there’s a lot of scary sounding words for your average infrastructure admin or cloud newbie. Five years ago, you could get by as a Sysadmin without knowing what GitHub, Terraform, and GitOps were. Now? Not so much. Before I dig too deep into the tech, I’d first like to put your potentially troubled mind at ease. If you’re a seasoned DevOps veteran, you can probably skip to the next section.
Let’s start with GitHub and GitHub Actions. The venerable GitHub is a place for you to store version controlled repositories of code. If you’re a more traditional Sysadmin, you might not have much use for code repositories, since you don’t have code per se. But as you move into the world of Infrastructure as Code, now you do have code you’d like to store somewhere. GitHub is one of several excellent options.
GitHub Actions is simply a workflow engine. It’s a set of instructions for GitHub to execute when an event occurs, like when you push new code to the repository. It can be used for Continuous Integration and Delivery (there I go use DevOps’y terms again), but you can really have it listen for any type of event and take just about any kind of action that is supported by an API. We joked in the video that you could have GitHub Actions order you a pizza from Dominos using Terraform. But that is a real thing you could do! Not especially useful for standing up infrastructure perhaps, but it’s a fun example.
Okay, so GitHub is a place to store your code. And GitHub Actions is a workflow engine that can do something with your code. What type of code might you be working with? Terraform code of course! Terraform is an application from HashiCorp that automates the deployment and management of infrastructure. Terraform code is expressed in either JSON or HashiCorp Configuration Language, and it is evaluated and executed by the Terraform binary. Terraform has a general workflow of initialize, plan, and apply. Initialize prepares the code to be executed by downloading providers and modules and setting up the state data backend. Plan evaluates the code against the target environment and shows you a list of changes it would make to have the target environment match the desired state expressed by the code. Apply makes the changes outlined by plan.
Wait. Did someone say workflow? Sweet. We can use GitHub Actions to execute the standard Terraform workflow. But when should the actions kick off? That brings us to the final term, GitOps.
GitOps is a extension of DevOps, and it is premised on the idea that your workflow should be driven by events in your Git-based repository. Git is the magic behind GitHub and most other source control repository systems.
Without getting too deep into the world of Git, we can think of the code we are working with on our workstation as local, and the code stored up on GitHub as remote. Locally, I could be working on some updates for my Terraform code. When I think it’s in a good state, I will commit the change to source control locally, and then push that change to remote. That push is one possible event to listen for on the GitHub actions side.
When developers - like you and me? - are working on a new feature or big change, the common practice in Git is to create a new branch based on the main branch. Once we’ve pushed our new branch to remote and tested things out, we can create a pull request to merge our branch into main. That’s another event we want to listen for!
Finally, once we’ve decided to accept the pull request, we merge the code into the main branch. A merge is really just a push from one branch to another, which means we have to listen for push events on the main branch.
I think that covers the background, and hopefully I’ve demystified some of these fancy terms. If not, there are literally whole books dedicated to each topic. Go forth and consume!
GitHub Actions looks for YAML files in the directory .github/workflows. The contents of those files determine what events to listen for and what actions to take. The actions are broken up into jobs that are assigned to a runner, typically hosted by GitHub. Each job is made up of steps for the runner to execute.
To summarize from the previous section, we are looking for three different events: A push on non-main branches, a pull request against the main branch, and a push on the main branch. What might we want to do for each event? Pushes on non-main branches could be checked to ensure initialization works and that the code is valid and properly formatted. A pull request against main means that code could be ready for production roll-out, so we probably want to run a plan to see what changes are being made. And then the merge to main would mean the code looks good and we want to use it, meaning we should run an apply. With that in mind, let’s check out the beginning of our GitHub Actions file.
You can find the file, as well as the rest of the demo on the ado-labs-github-actions GitHub repository.
name: 'Terraform'
on: [push, pull_request]
env:
TF_LOG: INFO
We have named the action ‘Terraform’ and let GitHub know that it should run this action when there is a push or pull_request event on the repository. We can also set global environment variables for all jobs, which in our case we are setting the level of Terraform logging to INFO.
Next up we can create our jobs.
jobs:
terraform:
name: 'Terraform'
runs-on: ubuntu-latest
# Set the working directory to main for the config files
defaults:
run:
shell: bash
working-directory: ./main
We are creating a single job here and running it on a GitHub hosted runner using the latest Ubuntu flavor runner machine. We are also going to set some defaults for all the steps in the job, setting the shell to bash and the working directory to ./main. That is where out Terraform code lives.
With the defaults established, we are now going to create the steps. First up, we have to do a little prep work:
steps:
# Checkout the repository to the GitHub Actions runner
- name: Checkout
uses: actions/checkout@v2
# Install the preferred version of Terraform CLI
- name: Setup Terraform
uses: hashicorp/setup-terraform@v1
with:
terraform_version: 1.0.10
The Checkout step performs a checkout of the code in our repository so the runner can do it’s thing. The Setup Terraform step installs the Terraform binary on the runner, allowing us to run Terraform commands against our code.
With our code and Terraform available on the runner machine, we can start the standard Terraform workflow. The first step will be Terraform Init, which needs to run regardless of whether we are in the plan phase or the apply phase.
- name: Terraform Init
id: init
env:
ARM_CLIENT_ID: ${{ secrets.ARM_CLIENT_ID }}
ARM_CLIENT_SECRET: ${{ secrets.ARM_CLIENT_SECRET }}
ARM_TENANT_ID: ${{ secrets.ARM_TENANT_ID }}
ARM_SUBSCRIPTION_ID: ${{ secrets.ARM_SUBSCRIPTION_ID }}
RESOURCE_GROUP: ${{ secrets.RESOURCE_GROUP }}
STORAGE_ACCOUNT: ${{ secrets.STORAGE_ACCOUNT }}
CONTAINER_NAME: ${{ secrets.CONTAINER_NAME }}
run: terraform init -backend-config="storage_account_name=$STORAGE_ACCOUNT" -backend-config="container_name=$CONTAINER_NAME" -backend-config="resource_group_name=$RESOURCE_GROUP"
Terraform needs to download the providers and modules used by our code and prepare the state data backend. We are running the terraform init command along with a bunch of arguments that establish where the state data will live.
The state data backend is using azurerm and we need to supply credentials to access the Azure storage account. The values for the backend and Azure credentials can be passed using environment variables, which is why we have an env block that creates those environment variables. The environment variables starting with ARM are the Azure credentials, which Terraform knows to check for when the azurerm backend or provider is used.
What about the values? Where are those coming from? Each value is stored as a Secret in the GitHub repository:
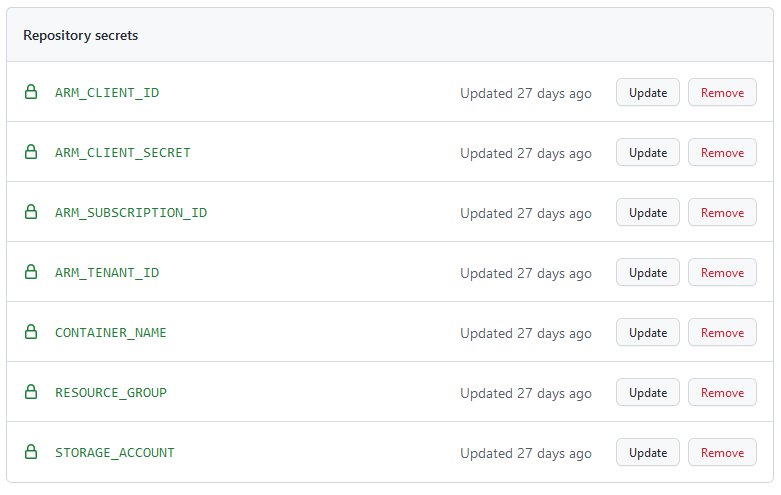
And referenced by using the syntax ${{ secrets.NAME }}. The runner will load those values dynamically and store them in environment variables, meaning the values are never written to disk on the runner or stored in the logs. Given the sensitive nature of our Azure credentials, that’s probably a good thing!
Moving to the Terraform Plan step, we are going to run this step only if the event is a pull request.
- name: Terraform Plan
id: plan
env:
ARM_CLIENT_ID: ${{ secrets.ARM_CLIENT_ID }}
ARM_CLIENT_SECRET: ${{ secrets.ARM_CLIENT_SECRET }}
ARM_TENANT_ID: ${{ secrets.ARM_TENANT_ID }}
ARM_SUBSCRIPTION_ID: ${{ secrets.ARM_SUBSCRIPTION_ID }}
if: github.event_name == 'pull_request'
run: terraform plan -no-color
Once again we’ll need those Azure credentials, this time for the azurerm provider used in our code, so we are loading the required environment variables. Next, we have an if statement that checks to see if this is a pull request event. If that statement evaluates to true, the step will execute and run terraform plan.
The point of running terraform plan is to see what changes Terraform would make to our target environment. The output of the plan command will be in the runner logs, but wouldn’t it be nice if we could capture the output and add it to the pull request as a comment? Yup, it sure would be.
- name: add-plan-comment
id: comment
uses: actions/github-script@v3
if: github.event_name == 'pull_request'
env:
PLAN: "terraform\n${{ steps.plan.outputs.stdout }}"
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
script: |
The comment step uses the GitHub script action to run Bash script on the runner as defined by the script block. This step will only run if the event is a pull request, just like our Terraform Plan step. In the environment variable PLAN we are storing the stdout of the Terraform Plan step. That’s right, you have access to the standard output of any previous steps in the workflow.
In the Bash script, we are going to post a comment to the pull request, which requires authentication. In the repository there is a pre-existing secret called GITHUB_TOKEN that the runner can grab and use to execute commands against the repository.
Let’s take a look at the script being run by this step:
script: |
const output = `#### Terraform Format and Style 🖌\`${{ steps.fmt.outcome }}\`
#### Terraform Initialization ⚙️\`${{ steps.init.outcome }}\`
#### Terraform Validation 🤖${{ steps.validate.outputs.stdout }}
#### Terraform Plan 📖\`${{ steps.plan.outcome }}\`
<details><summary>Show Plan</summary>
\`\`\`${process.env.PLAN}\`\`\`
</details>
*Pusher: @${{ github.actor }}, Action: \`${{ github.event_name }}\`, Working Directory: \`${{ env.tf_actions_working_dir }}\`, Workflow: \`${{ github.workflow }}\`*`;
github.issues.createComment({
issue_number: context.issue.number,
owner: context.repo.owner,
repo: context.repo.repo,
body: output
})
First we have to construct our output for the comment. Basically it will summarize the results of previous steps taken by the script. We didn’t run an fmt or validate step, but if we had, the outcome or output would be included here.
The initialization and plan steps are referenced, and the full output of the plan is hidden using a details HTML tag.
Once we have constructed our output, the function createComment is invoked to create the comment in the referenced pull request. Fun fact, a pull request is really just a special type of issue, which is why you see the issue_number argument and context.issue.number reference.
The code above is rendered like this in the pull request comments:
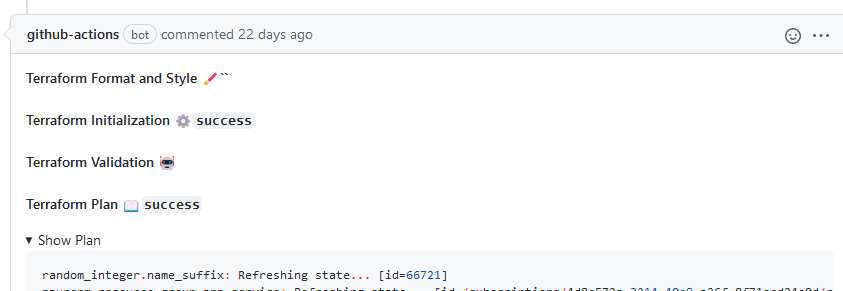
The format and validation steps are blank because we didn’t run those steps. The initialization and plan were both successful, and the full plan is available by expanding Show Plan.
Anyone reviewing the pull request for approval doesn’t have to dig into logs to find the plan output, they can just expand the comment in the pull request added by this step.
Finally we can move on to the last step, Terraform Apply, which applies the code if the pull request is approved.
- name: Terraform Apply
if: github.ref == 'refs/heads/main' && github.event_name == 'push'
env:
ARM_CLIENT_ID: ${{ secrets.ARM_CLIENT_ID }}
ARM_CLIENT_SECRET: ${{ secrets.ARM_CLIENT_SECRET }}
ARM_TENANT_ID: ${{ secrets.ARM_TENANT_ID }}
ARM_SUBSCRIPTION_ID: ${{ secrets.ARM_SUBSCRIPTION_ID }}
run: terraform apply -auto-approve
Merging a pull request is a push event on the target branch - main in our case, so we have an if statement checking for that event. Below the if statement, we once again establish the credentials needed to access the target environment in Azure, and run a terraform apply with the -auto-approve flag, which skips the usual prompt on an apply.
Our GitHub Actions file follows a GitOps workflow from the initial push of a feature branch, to a pull request to merge the feature branch into main, to the merge being approved and pushed to the main branch. Along the way the code is initialized, a Terraform plan is run and verified, and the code is applied to the target environment.
The GitHub Actions file used for the demonstration doesn’t have a lot of bells and whistles, but you can certainly add some! At a minimum, you could add in steps to run fmt and validate on a push or a pull request. You could also integrate a tool like Checkov to do static code analysis of your Terraform code. You could even deploy the code to a test environment and run something like Terratest to validate it functions properly. Starting with the basic framework from this demo, the sky is the limit.
May 23, 2026

May 4, 2026


